

Le persone quando parlano usano stili di pronuncia diversi a seconda del contesto. Gli assistenti digitali come Alexa (di Amazon), Assistente (di Google), Siri (di Apple), Cortana (di Microsoft) ed altri vengono ‘addestrati’ per poter parlare quanto meglio riescono in maniera simile a come parla una persona ‘reale’ anche se nessuno al momento è in grado di parlare in maniera naturale al cento per cento. Di positivo c’è che questi assistenti digitali risiedono nel cloud, il che significa che piu’ vengono usati dagli utenti e piu’ imparano modi di parlare diversi, potendo quindi migliorare senza obbligare gli utenti a cambiare i dispositivi che già hanno. Alexa di Amazon è l’assistente vocale più popolare, essendo il primo ad aver debuttato su uno smart speaker, nell’originale Amazon Echo nel 2015 negli Stati Uniti, dove gli utenti sono già oggi soddisfatti di come Alexa parla, mentre in Italia non si puo’ dire altrettanto in quanto solo da poche settimane parla l’italiano, ma possiamo stare tranquilli del fatto che migliorerà nei mesi a venire. I creatori di Alexa stanno comunque lavorando per migliorare il linguaggio in cui parla Alexa per renderlo ancora piu’ simile al linguaggio umano. E’ in sviluppo, in particolare, lo stile di linguaggio dal suono più naturale che hanno chiamato "stile giornalista", come riportato sul blog di Amazon rivolto agli sviluppatori che lavorano con Alexa (via The Verge).
Trevor Wood – un manager di scienze applicate – e lo scienziato Tom Merritt entrambi lavorano nel team di sviluppo del linguaggio in cui parla Alexa ed hanno spiegato nel suddetto blog che un giornalista televisivo, ad esempio, usa uno stile molto diverso quando parla dei titoli del giorno rispetto ad un genitore quando legge una favola della buonanotte al proprio bambino. Gli scienziati di Amazon hanno dimostrato che il sistema TTS (text-to-speech) usato da Alexa e da gran parte degli altri assistenti, che utilizza una rete neurale generativa, può imparare lo ‘stile del giornalista’ solo con poche ore di dati per l’addestramento. "Questo avanzamento spiana la strada ad Alexa e ad altri servizi per adottare stili di parlato diversi in contesti diversi, migliorando le esperienze dei clienti" ha spiegato Wood.
In altre parole, il team di Alexa di Amazon sta utilizzando l’apprendimento automatico per aggiungere una cadenza più naturale alla voce di Alexa, facendole ‘imparare’ lo stile dei giornalisti. Utilizzando la tecnologia "Neural text-to-speech" (NTTS) di Amazon, Alexa può intuire le variazioni nella pronuncia e applicarle al suo discorso, facendo succedere le parole in maniera piu’ simile ad una pronuncia naturale piuttosto che combinare parole mettono insieme brevi frammenti di parlato memorizzati in un database di audio, cosa che fanno al momento gli assistenti vocali.
Il sistema neurale TTS di Amazon comprende due componenti: (1) una rete neurale che converte una sequenza di fonemi – le più elementari unità di linguaggio – in una sequenza di ‘spettrogrammi’ o istantanee dei livelli di energia in diverse bande di frequenza; e (2) un vocoder, che converte gli spettrogrammi in un segnale audio continuo. Il primo componente del sistema è un modello sequenza-a-sequenza, nel senso che non calcola un determinato output esclusivamente dal corrispondente input, ma considera anche la posizione nella sequenza di output. Gli spettrogrammi che il sistema emette sono ‘spettrogrammi di melodia’, il che significa che le bande di frequenza sono scelte per enfatizzare le caratteristiche acustiche che il cervello umano utilizza quando elabora il parlato. Una volta formati i grandi set di dati usati per costruire sistemi di sintesi concatenativa di uso generale, questo approccio sequenza-a-sequenza produce voci di alta qualità e dal suono neutro.
Alexa – parlato concatenativo vs Neutral NTTS vs stile giornalista NTTS vs parlato di giornalista naturale
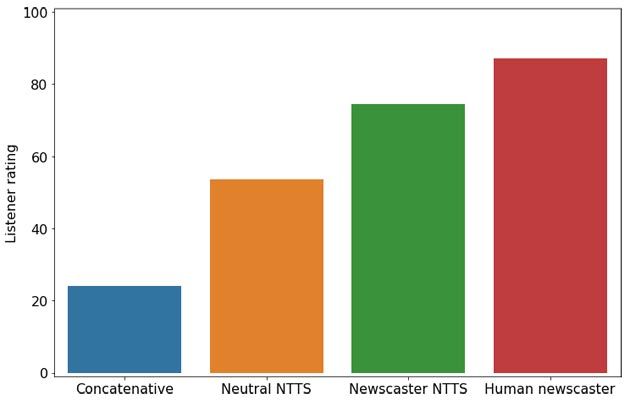
Per determinare se lo stile del giornalista (NTTS) fa la differenza per le esperienze degli ascoltatori, Amazon ha condotto un test percettivo su larga scala. E’ stato chiesto agli ascoltatori di valutare i campioni di parlato su una scala da 0 a 100, a seconda di quanto i loro stili di conversazione fossero adatti alla lettura di notizie. Nel test è stata inclusa la registrazione audio di un vero giornalista come riferimento. Gli ascoltatori hanno giudicato lo stile NTTS neutro migliore della sintesi concatenativa, riducendo del 46% la discrepanza tra i discorsi umani e sintetici. Rispetto allo stile NTTS neutro gli ascoltatori hanno pero’ preferito lo stile ‘giornalista’ NTTS. I risultati del test sono raffigurati nell’immagine qui sopra riportata.
In conclusione, mettendo da parte i tecnicismi, l’obiettivo di Amazon è quello di rendere Alexa ancora piu’ brava a parlare in maniera naturale dandole la capacità di capire il contesto delle frasi da pronunciare.
Link all’articolo completo sul blog di Amazon per approfondimenti qui: https://developer.amazon.com/it/blogs/alexa/post/7ab9665a-0536-4be2-aaad-18281ec59af8/varying-speaking-styles-with-neural-text-to-speech





